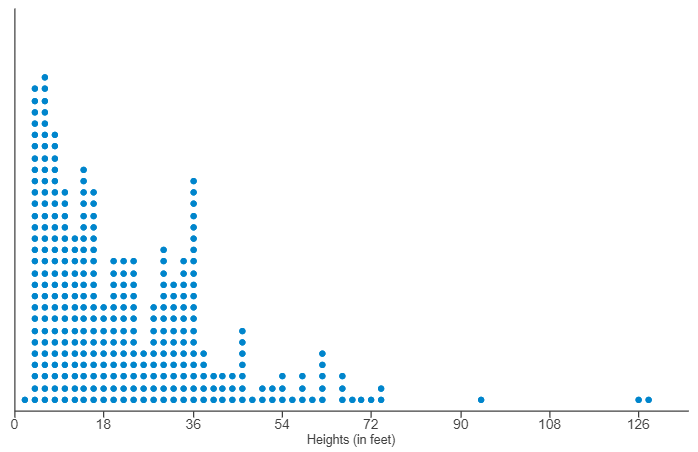
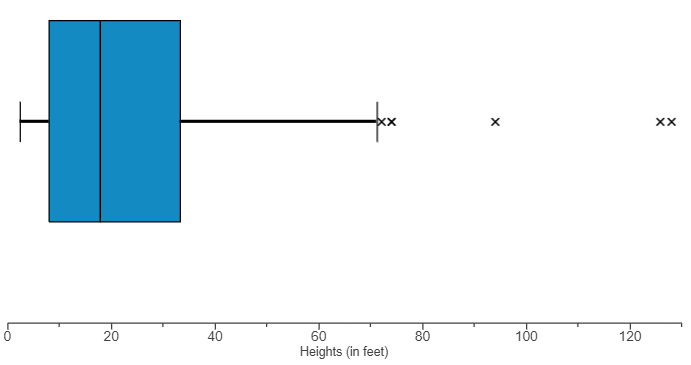
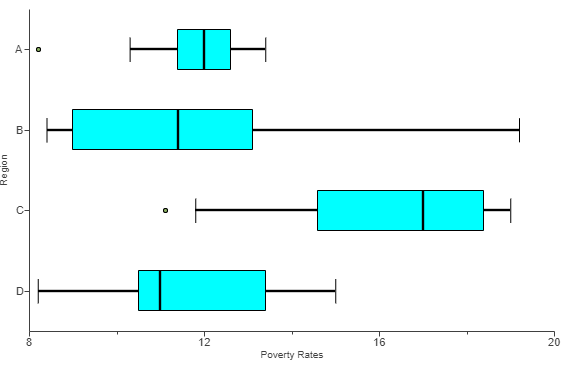
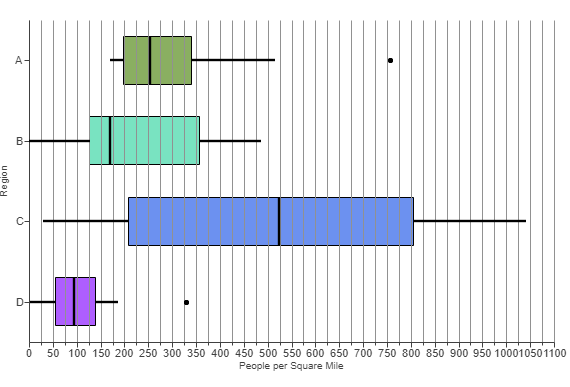
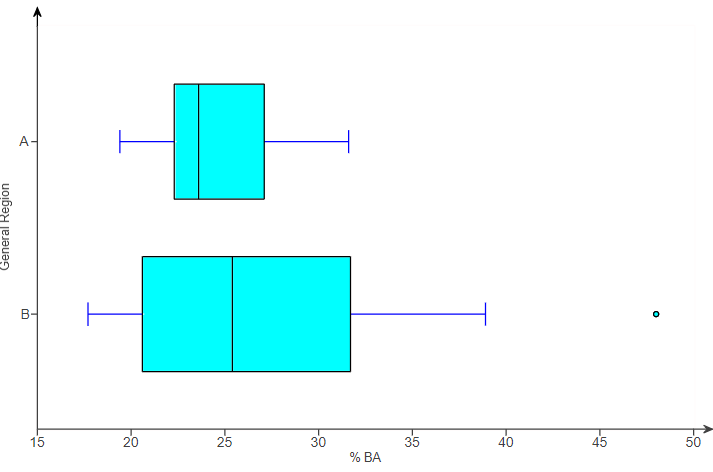
(9.) The boxplot displayed shows the average ticket price for four professional sports leagues.
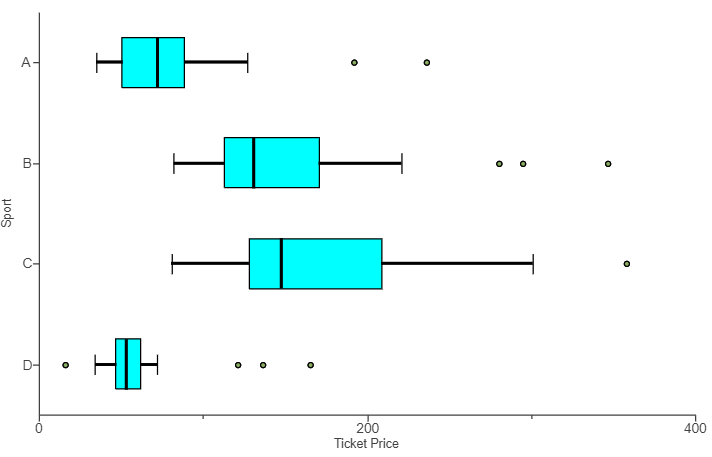
(a.) Which sport has the most expensive ticket prices?
(b.) Which sport has the least expensive ticket prices?
(c.) Compare the ticket prices for Sport A and Sport B.
In your comparison, compare the price of a typical ticket, the amount of variation in ticket prices, and the presence of any outliers in the data.
(a.) The sport with the most expensive ticket prices is Sport C because it has the greatest maximum ticket price.
(b.) The sport with the most expensive ticket prices is Sport D because it has the least minimum ticket price.
(c.) A typical ticket for Sport A is less expensive than a typical ticket for Sport B, since Sport A has a lower median than Sport B.
Sport B has more variability in ticket prices, as shown by a higher IQR (the length of the box...without the whiskers).
Sport A has potential outliers representing unusually high-priced tickets.
Sport B has potential outliers representing unusually high-priced tickets.
(a.) Which sport has the most expensive ticket prices?
(b.) Which sport has the least expensive ticket prices?
(c.) Compare the ticket prices for Sport A and Sport B.
In your comparison, compare the price of a typical ticket, the amount of variation in ticket prices, and the presence of any outliers in the data.
(a.) The sport with the most expensive ticket prices is Sport C because it has the greatest maximum ticket price.
(b.) The sport with the most expensive ticket prices is Sport D because it has the least minimum ticket price.
(c.) A typical ticket for Sport A is less expensive than a typical ticket for Sport B, since Sport A has a lower median than Sport B.
Sport B has more variability in ticket prices, as shown by a higher IQR (the length of the box...without the whiskers).
Sport A has potential outliers representing unusually high-priced tickets.
Sport B has potential outliers representing unusually high-priced tickets.